基于 jdk8 🔗 https://docs.oracle.com/javase/8/docs/api/index.html
Collection概览
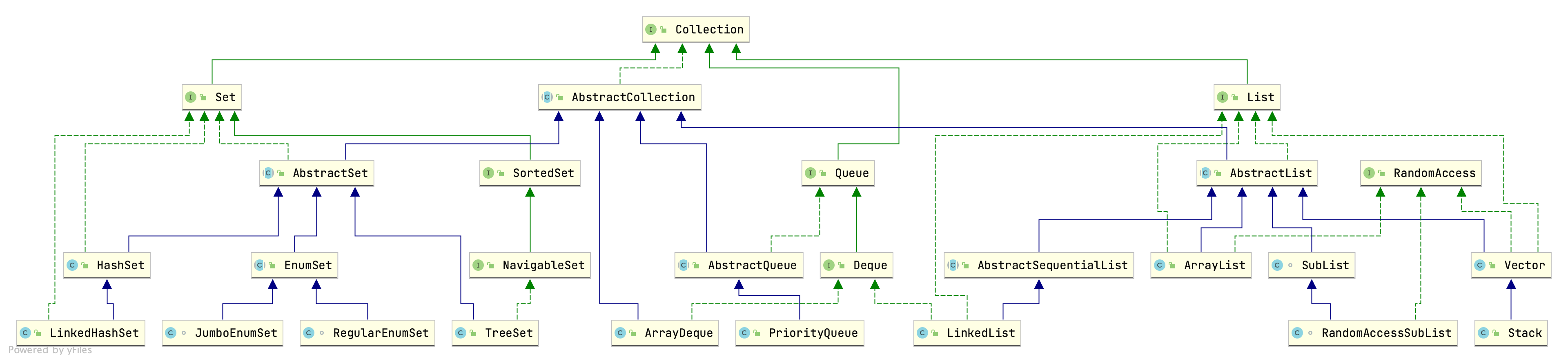
Collection i
集合层次结构中的根接口。集合表示一组对象,称为其元素。一些集合允许重复的元素,而另一些则不允许。一些是有序的,而其他则是无序的。 JDK不提供此接口的任何直接实现:它提供更具体的子接口(例如 Set和 List)的实现。所有通用的 Collection 实现类都应提供两个“标准”构造函数:一个void(无参数)构造函数(用于创建一个空集合)和一个带有单个参数类型的构造函数 Collection,它将创建一个新集合,其元素与其参数相同。不同的集合实现类对包含的元素有不同的限制。线程安全由实现者自己保证。对于集合直接或间接包含自身的自引用实例,某些执行集合的递归遍历的集合操作可能会失败。这包括 clone(),equals(),hashCode()和 toString() 方法。实现可以有选择地处理自引用场景,但是大多数当前实现不这样做。
AbstractCollection ac
此类提供了 Collection 接口的基本实现,以最大程度地减少实现新的集合所需的工作。
如要要实现一个不可变集合,只需要实现类重写iterator和size方法。iterator必须要实现hasNext和next方法。如果要实现一个可变集合,实现类必须要重写add方法。iterator必须要实现remove方法。
集合实现类应该提供一个无参构造器和一个接受Collection的初始化构造器。
AbstractCollection中提供的所有实现都是基于iterator实现。
List i
有序集合(也称为序列)。该接口可以精确控制列表中每个元素的插入位置。用户可以通过其整数索引(列表中的位置)访问元素,并在列表中搜索元素。
与集合不同,列表通常允许重复的元素,不限制具体的实现类允许多个null元素。
该接口提供了一个特殊的迭代器,称为 ListIterator,它允许元素插入和替换及双向访问,提供了一种方法来获取从列表中指定位置开始的列表迭代器。
List接口提供了两种方法来有效地在列表中的任意点插入和删除多个元素。
注意:如果列表允许添加自身,hashCode方法会由于循环嵌套抛出StackOverflowError。因此所有依赖equals的方法都会受到影响
RandomAccess i
此接口表示其实现类可以很快的恒定时间通过坐标访问元素,比如 ArrayList实现了此接口而 LinkedList没有实现。
AbstractList ac
此类提供 List 接口的基本实现,以最大程度地减少实现由“随机访问”数据存储(例如数组)支持的该接口所需的工作。对于顺序访问数据(例如链表),应优先使用 AbstractSequentialList 。
要实现一个不可修改的列表,只需要重写get/set方法的实现。
要实现一个可修改的列表,须另外重写 set方法(否则会抛出 UnsupportedOperationException)。如果列表是可变大小的,则必须另外重写 add 和 remove 方法。
ArrayList
List接口的数组实现。允许null。除了实现 List接口之外,应用程序可以通过使用 esureCapacity 操作在添加大量元素之前增加ArrayList实例的容量。这可以减少增量重新分配的数量。
此实现未同步。 如果多个线程同时访问 ArrayList实例,并且至少有一个线程在结构上修改列表,则必须在外部进行同步。(结构修改是添加或删除一个或多个元素或显式调整后备数组大小的任何操作;仅设置元素的值不是结构修改。)如果要同步需要使用 ` Collections.synchronizedList 进行包装。List list = Collections.synchronizedList(new ArrayList(…));`。此类在创建迭代器后任何操作都会判断modCount值是否改变来快速失败。在进行add、remove等操作时会递增modCount。
ArrayList由于使用的是数组,需要有一套扩容机制。其实现方式为:默认创建时使用一个哨兵对象,长度为0的数组。第一次扩容的默认大小为10。之后默认扩容大小为当前长度除2,但是不会超过 Integer.MAX_VALUE - 8。但是当一次扩容所需的大小超过默认大小时,比如addAll添加很多元素,就会直接扩到所需的大小,这时允许超过 Integer.MAX_VALUE - 8,所以在一些JVM上会有OOM风险。ArrayList的扩容代码在JDK8之前逻辑混乱,表述不清,虽然在JDK11中重构了一次,但是描述也很冗余。直到JDK17中的实现才真正清晰明确。
ArrayList中的元素插入、删除、扩容等所有需要移动元素的方法,都是使用 Arrays.copyOf方法实现。
ArrayList中有两个内部类 Itr和 ListItr用于实现迭代器,但其还是基于ArrayList内部数据实现,只是缓存了一些迭代指针等数据。
ArrayList的subList方法返回的并不是一个新的ArrayList,还是其内部类 SubList。SubList也是基于ArrayList的原始内部数据实现,只作为一个视图,只是缓存了当前subList的边界等数据。因此在使用SubList的时候需要谨慎。
SubList
AbstractList 的内部类、实现类。内部保存了子List的长度和父List的长度子列表与父列表的数据修改会互相影响,子列表的长度变化会影响父列表,但是父列表的长度变化会导致子列表执行方法抛异常。
RandomAccessSubList
AbstractList 的内部类、实现类。继承 SubList,由于 SubList没有直接实现 RandomAccess接口,所以其作用只是标识一个实现了 RandomAccess接口的 SubList。
AbstractSequentialList ac
此类提供了 List 接口的基本实现,以最大程度地减少实现由“顺序访问”数据存储(例如链表)支持的该接口所需的工作。对于随机访问数据(例如数组),应优先使用 AbstractList。
LinkedList
List和 Deque 接口的双链表实现。允许null元素。支持peek、pop、push、offer、poll等操作。
其根据索引查找数据的操作会判断当前索引落在中间之前,还是中间之后,然后选择从前或从后遍历重找元素。
其根据数据查找索引的操作,需要从前往后遍历。
此实现未同步,如果需要同步应使用 Collections.synchronizedList来进行包装。List list = Collections.synchronizedList(new LinkedList(...));
Vector
与ArrayList的不同是,所有修改的方法上都有 synchronized 修饰。每次扩容默认扩容一倍。
Stack
所述Stack类表示对象的后进先出(LIFO)堆栈。它继承了 Vector类,并通过Vector提供的方法扩展了push、pop、peek方法,这些操作允许将Vector视为堆栈。首次创建堆栈时,它不包含任何项目。在需要堆栈时应优先使用 Deque类。 Deque<Integer> stack = new ArrayDeque<Integer>();。
Set i
不包含重复元素的集合。最多包含一个空元素。❗特别注意集合元素中不能有可变对象。
AbstractSet ac
此类提供Set 接口的基本实现,以最大程度地减少实现此接口所需的工作。通过扩展此类来实现集合的过程与通过扩展 AbstractCollection 来实现 Collection 的过程相同,不同之处在于,此类的子类中的所有方法和构造函数都必须服从 Set 接口施加的附加约束(例如, add方法不得允许将一个对象的多个实例添加到集合中)。
HashSet
依赖HashMap实现的HashSet。内部有一个全局静态哨兵对象来当做HashMap的value。其中的一个构造函数提供初始化容量 (Math.max((int) (param.size()/.75f) + 1, 16))。
LinkedHashSet
继承了HashSet,HashSet中为LinkedHashSet专门提供了一个构造方法,使用 LinkedHashMap作为内部存储来实现LinkedHashSet :
// dummy参数没有使用,只是个构造函数多态辅助标识
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
TreeSet
使用NavigableMap实现Set,默认使用TreeMap,可以通过构造函数指定其他的实现类Map。
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
private transient NavigableMap<E,Object> m;
private static final Object PRESENT = new Object();
//使用自定义实现类Map构造TreeSet
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
//使用默认TreeMap构造TreeSet
public TreeSet() {
this(new TreeMap<E,Object>());
}
...
}
EnumSet<E extends Enum> ac
不允许空元素。用于枚举类型的 Set实现,枚举集中的所有元素都必须来自创建集时显式或隐式指定的单个枚举类型。枚举集在内部表示为位向量。这种表示非常紧凑和高效。此类的时空性能应足够好,以使其可以用作传统的基于int的“位标志”的高质量,类型安全的替代方法。如果批量操作(例如containsAll和keepAll)的参数也是一个枚举集,它们也应该非常快速地以恒定时间运行。EnumSet不同步。
使用以下方法创建新的空集合:
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) {
Enum<?>[] universe = SharedSecrets.getJavaLangAccess()
.getEnumConstantsShared(elementType);
if (universe.length <= 64)
return new RegularEnumSet<>(elementType, universe);
else
return new JumboEnumSet<>(elementType, universe);
}
JumboEnumSet<E extends Enum>
用于EnumSet的私有实现类,用于“巨大”枚举类型(即元素多于64个的元素)
private long elements[];
private int size = 0;
RegularEnumSet<E extends Enum>
枚举集的私有实现类,用于“常规大小”枚举类型(即枚举常数为64或更少的枚举)
private long elements = 0L;
SortedSet i
定义有序Set的接口。subSet的操作是前闭后开,如果需要前开或者后闭请参考 https://stackoverflow.com/questions/17380051/adding-0-to-a-subset-range-end。
NavigableSet i
提供一种可以在Set内部进行搜索查询的接口。提供了lower、floor、ceiling和higher方法返回小于、小于或等于、大于或等于和大于给定元素的元素,如果没有这样的元素则返回null。可以按升序或降序访问遍历NavigableSet。正序的视图性能可以比降序的快。
该接口还定义了pollFirst和pollLast方法,它们返回和删除最低和最高元素,如果存在,则返回null。方法subSet、headSet和tailSet与类似命名的SortedSet方法的不同之处在于接受描述下限和上限是包含还是排除的附加参数。任何NavigableSet的子集都必须实现NavigableSet接口。
在允许null元素的实现中,导航方法的返回值可能不明确。但是,即使在这种情况下,也可以通过检查 contains(null)来消除歧义。为避免此类问题,鼓励此接口的实现不允许插入null元素。(请注意, Comparable元素的排序集本质上不允许null 。)
方法 subSet(E, E)、headSet(E)和 tailSet(E)被指定返回SortedSet以允许对SortedSet的现有实现进行兼容改造以实现NavigableSet,但鼓励此接口的扩展和实现覆盖这些方法返回NavigableSet。
Queue i
设计用于在处理之前容纳元素的集合。除了基本的收集操作外,队列还提供其他插入,提取和检查操作。这些方法中的每一种都以两种形式存在:一种在操作失败时引发异常,另一种返回一个特殊值(根据操作而为null或false)。插入操作的后一种形式是专为与容量受限的 Queue实现一起使用而设计的;在大多数实现中,插入操作不会失败。该接口未定义阻塞队列的方法。不允许插入空值,因为poll方法空值认为不包含任何元素。
| Throws exception | Returns special value | |
|---|---|---|
| Insert | add(e) | offer(e) |
| Remove | remove() | poll() |
| Examine | element() | peek() |
AbstractQueue ac
此类提供某些 Queue 操作的基本实现。不允许空值。
PriorityQueue
基于优先级堆的无边界优先级队列。里面的元素自然排序,或者创建时提供的 Comparator。不允许插入空值,即使基于自然排序依然需要元素实现比较。队列的头是最小元素,如果有多个最小元素将是其中之一。poll, remove, peek, element方法从队列头操作。队列虽然是无界的,但内部有容量来记录数组大小,会自动增长。其提供的 iterator()方法不提供有序遍历,请使用 Arrays.sort(pq.toArray())。此类线程不安全,可以使用 PriorityBlockingQueue代替。此类 ` (offer, poll, remove() and add)方法有 O(log(n))时间复杂度,remove(Object) and contains(Object) `有线性复杂度,(peek, element, and size)有常数复杂度。
Deque i
支持在两端插入和删除元素的线性集合。”double ended queue”的缩写。不支持索引访问。不应该向其插入空值,一般空值意味着队列为空。
| Throws exception | Special value | Throws exception | Special value | |
|---|---|---|---|---|
| Insert | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| Remove | removeFirst() | pollFirst() | removeLast() | pollLast() |
| Examine | getFirst() | peekFirst() | getLast() | peekLast() |
该接口扩展了 Queue接口。当双端队列用作队列时,将导致FIFO(先进先出)行为。元素在双端队列的末尾添加,并从开头删除。
| Queue 方法 | 等效Deque方法 |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
双端队列也可以用作LIFO(后进先出)堆栈。此接口应优先于旧 Stack类使用。当双端队列用作堆栈时,元素从双端队列的开头被压入并弹出。
| 堆叠方式 | 等效Deque方法 |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
ArrayDeque
Deque接口的可调整大小的数组实现。阵列双端队列没有容量限制。它们会根据需要增长以支持使用。它们不是线程安全的。在没有外部同步的情况下,它们不支持多个线程的并发访问。空元素是禁止的。此类可能比 Stack用作堆栈时要快 ,并且比 LinkedList 用作队列时要快。
Map概览
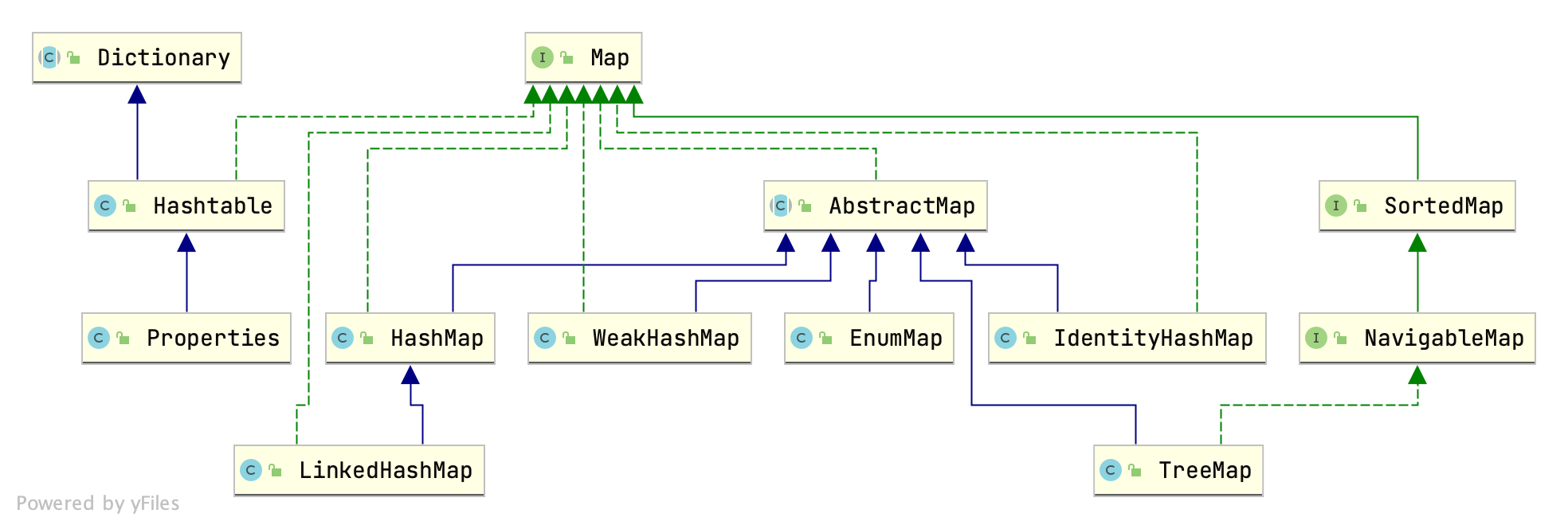
Map
将键映射到值的对象。映射不能包含重复的键;每个键最多可以映射到一个值。 该接口代替了 Dictionary类,后者是一个完全抽象的类,而不是一个接口。 Map接口提供了三个集合视图,这些视图允许将Map的内容视为一组键,一组值或一组键-值映射。映射的顺序定义为映射的集合视图上的迭代器返回其元素的顺序。一些Map实现(例如TreeMap类)对其顺序做出特定的保证。其他的(例如HashMap类)则没有。 注意:如果将可变对象用作Map键,则必须格外小心。如果在对象是映射中的键的情况下以影响等值比较的方式更改对象的值,则不会指定映射的行为。
AbstractMap<K,V> ac
Map接口的一些骨架实现。几乎需要全部重写。
HashMap<K,V>
⚠️ 以下所有提到的“容量”都是指代HashMap中table的大小
基于哈希表的Map实现类。允许null作为键或者值。不保证顺序,且不保证顺序不会发生变化。
get 和 put 操作有恒定的时间性能,集合视图的操作(keySet、values、entrySet)迭代需要的时间与容量加上大小成正比。因此如果迭代性能很重要,初始容量不要太高或负载因子不要太低。
HashMap的实例有两个影响其性能的参数:初始容量和负载因子。容量是哈希表中的桶数,初始容量只是哈希表创建时的容量。负载因子触发扩容的阈值。当哈希表中的 ⚠️ 所有条目数超过负载因子和当前容量的乘积时,对哈希表进行重新哈希(即重建内部数据结构),扩容至大约两倍(极限是1«30)的桶数。
默认负载因子 (0.75) 在时间和空间成本之间提供了良好的折衷。较高的值会减少空间开销,但会增加查找成本(反映在HashMap类的大多数操作中,包括get和put )。在设置其初始容量时,应考虑映射中的预期条目数及其负载因子,以尽量减少重新哈希操作的次数。如果初始容量大于预期的最大条目数除以负载因子,则能避免在填充的时候频繁发生重新哈希操作。
如果要在一个HashMap实例中存储许多映射,则创建具有足够大容量的映射将比让它根据需要执行自动重新散列以增加表来更有效地存储映射。当遇到具有相同hashcode的键时,如果键是Comparable的,会使用compare来处理。
此实现是不同步的,需要在外部进行同步。或使用 Collections.synchronizedMap。HashMap返回的视图迭代器都是快速失败的,使用标记判断是否发生过修改操作,在并发修改后,会抛出 ConcurrentModificationException。只能使用这个异常来检查错误,不能用于逻辑判断。
hash 值只用来定位 bin 位置,之后还需要遍历 bin 中的元素根据 equals 方法判断键是否相等。
Hash 冲突处理
解决冲突的两种常用方法是使用链表和开放寻址,Java 中的 HashMap 选择的是链表法。
计算键的hash值
static final int hash(Object key)
虽然常见的对象的hashCode已经分布的很合理了,但是由于HashMap在计算元素的位置时使用二次掩码取余算法代替除法取余。当容量较小时(也就是掩码有效位数少时),有一些对象hashCode的分布会发生冲突。比如已知的在小容量的表中保存连续的 Float 类型整数,他们的低位都是 0 (浮点类型存储见浮点与二进制转换),在进行掩码运算时它们就会发生冲突。
因此 HashMap 在计算hash值的时候使用了高位向低位传播的方式。在位扩展的速度、实用性、和质量之间进行折衷,在已经使用了红黑树来处理 bin 中大量冲突的情况下。使用最轻量的方式来处理剩下的小部分情况,进行位移和异或。否则由于表大小(掩码有效位数),这些高位将永远无法用于索引计算。
初始化
提供了4个构造函数进行初始化,初始化时只能设置扩容阈值 threshold 和负载因子 loadFactor,真正的申请内存创建表延迟到了扩容方法中。初始化方法虽然提供了初始容量参数 initialCapacity ,但是该初始容量并没有被直接使用,而是通过 tableSizeFor 方法计算了大于等于给定初始容量的 2 的倍数的一个容量,并赋值到了 threshold 用于第一次初始化容量。
容量为什么一定要是2的倍数
如果用取余(符号相同时取余和取模是一样的计算,因此下文可能对两者混用)的方法计算元素的位置,取余计算会使用累加器,HashMap 作为 JDK 提供的功能使用频率极高,任何一点性能上的损失都会被无限放大。因此选用了轻量级的位运算来进行模运算,这个时候就需要容量是 2 的倍数才能方便计算。计算方法是把容量减一当作掩码进行按位与计算: (n - 1) & hash 来获取元素的位置。例如:
0011 0110 (hash值)
& 0000 1111 = 0001 0000 - 1 (掩码)
= 0000 0110 = hash对0001 0000取模 (按位与)
负载因子的取值
负载因子并没有限制一定是小于 1 的浮点数,负载因子可以大于 1,只要其满足 loadFactor > 0 && !Float.isNaN(loadFactor) 。
在C#中的负载因子是0.72,所以 0.75 并不是一个通过精密推导可以计算出来的完美取值,只是有一个合理的区间。在常理上其取值的合理范围在 0.5~1 。通过不发生碰撞的概率和取值极限推导计算其“应该“等于 ln2 = 0.693 。然后因为 HashMap 的初始容量是 16 ,也就是说只有 0.625(5/8),0.75(3/4),0.875(7/8) 这几个取值时初始阈值正好是整数。那么 0.75 其实就是一个折中的选择。
扩容
HashMap 在创建时只设置了一些配置参数,真正的初始化操作延迟到了扩容阶段。在扩容时确定要申请新的空间大小有 种情况:
- 第一次扩容,也就是第一次 put 数据的时候,且初始化时没有设置初始容量 👉 使用默认容量 16 ,使用默认阈值 16*0.75=12。
- 第一次扩容,也就是第一次 put 数据的时候,初始化时设置了初始容量 👉 使用设置的初始容量(⚠️ 初始容量经经过修剪),计算阈值为最大容量或者(初始容量乘负载因子)。
- 非第一次扩容,如果容量已经到了最大容量,就把阈值也设置为最大容量。否则最大容量扩充一倍(左移一位)。如果此时容量小于
DEFAULT_INITIAL_CAPACITY,新阈值就通过容量乘负载因子计算而得;但是当容量大于等于DEFAULT_INITIAL_CAPACITY时,新阈值就会通过位移来翻倍。原因是负载因子是个浮点数,当容量太小的时候,翻倍操作会扩大误差。比如当容量为2负载因子为0.75时,此时阈值等于$2 \times 0.75 = 2$,当容量翻倍时阈值等于$4 \times 0.75 = 3$,如果阈值通过翻倍计算就会是4,和3的误差相对容量来说较大。
扩容后容量翻倍(桶数量翻倍),对扩容前的位置,及每个位置上的元素进行双层遍历,进行 rehash 操作。然后针对两种类型有两种不同的处理方式。数据结构可以通过节点类型进行区分,Node 类型当前就是链表结构,TreeNode 类型当前就是树结构。
再 hash 操作
⚠️ oldCap 指扩容前的容量,也就是扩容前 table 的大小。
虽然节点有两种数据类型,但是对每个元素的 rehash 操作是一样的。因为红黑树的 TreeNode 类型同时也保存了链表结构,rehash 操作把每个桶都按照链表进行拆分,根据 hash & oldCap 是否等于 0 把原来位置上的链表拆分成低位和高位两条链表。低位链表还在原来的位置,高位链表移动到扩容后的位置 n + oldCap。之后再对两条已经完成 rehash 的链表根据情况进行处理。
HashMap 中的 hash 操作是对元素的 hash 值与 容量-1 进行按位与计算,而容量是2的倍数。
0011 0110 (hash值)
& 0000 1111 = 0001 0000 - 1 (掩码)
= 0000 0110 = hash对0001 0000取模 (按位与)
因为 HashMap 每次扩容都是 容量*2,在位计算上就是左移了一位:
0000 1000 -> 0001 0000
而对于新的容量进行 hash 操作与当前的 hash 结果对比:
注意这一列
↓
0001 0000 - 1 = 0000 1 111 (掩码)
& 0011 1 100 (hash值)
= 0000 1 100 (结果)
0000 1000 - 1 = 0000 0 111 (掩码)
& 0011 1 100 (hash值)
= 0000 0 100 (结果)
可以看出来,只有 oldCap 二进制中唯一的一个 1 的位置计算结果发生了变化。所以 HashMap 中的 rehash 操作使用的是 hash & oldCap 是否等于 0,等效于重新进行 hash 计算。等于 0 位置没有变化,不等于 0 位置移动到高位,而高位位置就是 n + oldCap 和重新 hash 的结果是一样的。这样的好处是可以减少一步 hash 操作时对于容量减 1 的步骤。
节点是 Node 类型,数据结构是链表
当前节点是 Node 类型,说明在扩容之前的链表元素少于等于 6 个,所以即使扩容后进行 rshash ,桶中元素数量只会更少。所以直接把 rshash 后拆分的两条链表移动到相应位置就完成了。
节点是 TreeNode 类型,数据结构是树
⚠️ TreeNode 类型的元素同时拥有链表和红黑树两种数据结构。且在链表中的顺序与红黑树中的顺序没有关联。
当前节点是 TreeNode 类型,说明在扩容之前的链表元素多于 6 个,拆分后的两条链表就会有两种情况,大小可以小于等于 6 个也可以大于 6 个。因此根据拆分后的大小情况进行 treeify 和 untreeify 操作。
treeify 把当前链表中混乱的红黑树结构进行重排。会得到一个新的树根节点,把这个新的根节点移动到链表结构的最前面。以方便进行红黑树查找操作。
untreeify 把当前链表中所有 TreeNode 类型的元素改成 Node 类型,链表结构不变,丢弃红黑树结构。
转换成树结构阈值8的取值
https://zhuanlan.zhihu.com/p/358138626
来自代码注释的一段实现说明:
Because TreeNodes are about twice the size of regular nodes, we use them only when bins contain enough nodes to warrant use (see TREEIFY_THRESHOLD). And when they become too small (due to removal or resizing) they are converted back to plain bins. In usages with well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution (http://en.wikipedia.org/wiki/Poisson_distribution) with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance, the expected occurrences of list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)). The first values are:
0: 0.60653066 1: 0.30326533 2: 0.07581633 3: 0.01263606 4: 0.00157952 5: 0.00015795 6: 0.00001316 7: 0.00000094 8: 0.00000006 more: less than 1 in ten million
The root of a tree bin is normally its first node. However, sometimes (currently only upon Iterator.remove), the root might be elsewhere, but can be recovered following parent links (method TreeNode.root()).
相关的知识:二项式分布的极限是泊松分布,泊松分布的极限是正态分布。
简述一下就是,把发生碰撞的频率 0.5 带入泊松分布的函数,求得发生 8 次碰撞的概率很低,低于设计者希望的阈值。
根据上述的资料,HashMap 的树结构,在设计之初就是一种性能补充的存在,这种结构占用内存大小会比常规节点大。在 key 的 hash 值合理分布的情况下其设计目的是尽量不使用上树结构。只有当遇到不合理的 hash 方法实现时,才使用红黑树结构来当做性能保障。而且当碰撞的数量减少时还会将红黑树结构重新转换成双向链表结构。
插入
插入的 hash 如果在空桶就可以直接插入。否则还需要根据头节点的类型来应对树结构和链表结构的插入,虽然两种类型,但都是先查找 key 是不是已经存在,如果存在就使用替换value来代替插入。
树结构插入
树结构需要准确找到要插入的位置,不能够多个元素公用位置,所以需要有明确的比较结果。因此当对比过程中遇到 hash 相同,但是值不相等的情况时:
- 首先判断 key 是否是
Comparable类型,使用compareTo()进行比较。 - 如果 key 没有实现
Comparable接口,尝试比较key.getClass().getName()。 - 如果比较类名还无法分出大小,就调用 native 方法
System.identityHashCode(),这时一定会出结果,因为把相等的情况直接定义了准确的大小System.identityHashCode(a) <= System.identityHashCode(b) ? -1 : 1。
当找到了准确的位置时,接下来就执行红黑树的插入逻辑,并把新的树根节点移动到双向队列头部。
链表结构插入
链表插入涉及到是否需要转换成树结构的问题,如果当前链表内元素数量少于 TREEIFY_THRESHOLD - 1 ,那就直接插入链表尾。
否则需要调用 treeifyBin() 转换成树结构,treeifyBin() 方法还会判断另一个条件当前 table 容量是不是小于 MIN_TREEIFY_CAPACITY = 64,如果是就会以 resize 代替转换成树结构。
MIN_TREEIFY_CAPACITY 的定义不小于 4 * TREEIFY_THRESHOLD = 32。因为默认扩容的阈值是0.75。假设取一个小于 32 的值 16 。小于 16 的容量已经不可能了,因为 TREEIFY_THRESHOLD 已经大于 8 * 0.75 = 6 ,冲突已经产生。那么如果容量是 16 ,16 * 0.75 = 12 只比 TREEIFY_THRESHOLD 大 4 。意味着结构转换操作之后随即就要进行 resize 操作。
因此在 treeifyBin() 方法中增加了一步判断当前容量大小,预防性的提前进行 resize 操作,减少操作次数。而 MIN_TREEIFY_CAPACITY 的取值,代码中只是在注释里提示了不能小于 4 * TREEIFY_THRESHOLD,所以它的真实取值可以更大,但不合适太大。
还有就是树结构只是 HashMap 的一个性能优化补充,主要还是应该以 resize 方法优先。如果容量很小,而单个桶内元素数量都达到了转换成树的情况,已经接近于单纯的红黑树,那么查找效率不会有提升。这种是 HashMap 一种畸形形态,不符合 HashMap 的定位。
LinkedHashMap<K,V>
继承了HashMap,通过封装或重写一部分HashMap方法实现功能。内部维护了HashMap所有元素的一个双向链表,LinkedHashMap保存了这个双向链表的头指针和尾指针。同时也继承了HashMap.Node,增加了前/后节点两个字段用于连接成双向链表。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>{
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
}
可以重写removeEldestEntry(Map.Entry)方法以在put数据时清理旧数据。
accessOrder字段为true,LinkedHashMap会以访问顺序排序。accessOrder字段为false会以插入顺序排序。LinkedHashMap不是线程同步的,需要外部实现同步。
IdentityHashMap<K,V>
一种用于极特殊情况的HashMap实现,在比较对象是否相等时使用的是==判断对象是否相等,而不是用equals。内部使用了一个Object数组实现的Hash表。当判断第一个位置已经有数据时寻找下一个位置,关键方法为:
private static int nextKeyIndex(int i, int len) {
return (i + 2 < len ? i + 2 : 0);
}
EnumMap<K extends Enum, V>
用于枚举类型键的Map实现,在创建EnumMap时指定键的枚举类,此后EnumMap中的所有键都必须是该类型。不允许插入空键,可以查询或删除空键。允许使用空值
内部使用一个Object数组实现,键和值的映射(通过键定位值的index)以枚举的常量声明顺序.ordinal()定位。也就是说这个Map中元素数量最多只能是该枚举的常量数量。
EnumMap是不同步的,需要外部进行同步。
WeakHashMap<K,V>
内部使用散列表的Map实现,Entry继承了WeakReference类,键使用了WeakReference包装。当键没有外部引用时,会被虚拟机进行回收。在WeakHashMap中的所有操作,都会触发expungeStaleEntries()对已经被回收的元素的清理。
对于使用 == 实现的 equals方法的键,这种对象不能被重建,如果键被回收则表示已经没有被引用,所以不会出现获取时发现元素已经被删除的情况。对于 String 这种特殊的能被重建的类,可能会出现键已经被回收了,但是使用重建的键查找时发现元素已经被删除的情况。
WeakHashMap 的行为与其他 Map 实现有不同,WeakHashMap 的键依赖于GC,在后台被清理。也就是说即使在同步方法内操作,其元素也会发生变化,大小也会不断减少。
需要注意 WeakHashMap 中的值不应该拥有其键的强引用。如果其值也不需要被强引用可以使用 WeakReferences 进行包装:m.put(key, new WeakReference(value))。
Dictionary<K,V> ac
已经被弃用的抽象类。
Hashtable<K,V>
所有方法都加了同步,已经不建议使用。建议使用 HashMap 或 ConcurrentHashMap 代替。
内部使用数组加链表实现。
Properties
Properties 保存一组键值对的属性配置,键和值都是字符串,继承自Hashtable。可以从流中加载也可以写入到流。Properties 中可以定义一组默认值,如果找不到键会去默认值中查找。
因为 Properties 继承自 Hashtable,虽然可以调用put 和 putAll 方法,但是不要尝试,会使得该属性对象受损。在受损的对象上再调用 Properties 方法会失败。
有一个内部类 LineReader 从输入流中读取所有行,会跳过所有注释行和空白行,并过滤没一行开头的空白字符。返回当前行的字符长度并把当前行数据存储在lineBuf中。
还有一个内部类 XmlSupport 用于加载外部Xml工具。
SortedMap<K,V> i
进一步提供其键的总体排序的Map。通常在排序的Map创建时提供的Comparator来对地图进行排序。遍历排序后的地图的集合视图(由entrySet,keySet和values方法返回)时,将反映此顺序。
NavigableMap<K,V> i
使用导航方法扩展的SortedMap返回给定搜索目标的最接近匹配项。方法lowerEntry、floorEntry、ceilingEntry和higherEntry返回与键关联的Map.Entry对象,分别小于、小于或等于、大于或等于和大于给定键,如果没有这样的键则返回null。同样,方法lowerKey、floorKey、ceilingKey和higherKey仅返回关联的键。所有这些方法都是为定位而不是遍历条目而设计的。
TreeMap<K,V>
基于红黑树的NavigableMap实现。内部维护一个红黑树,各节点保存了key和value。可以对元素进行导航定位。
其他
Exception
IllegalFormatException
当格式字符串包含非法语法或与给定参数不兼容的格式说明符时抛出未经检查的异常。仅应实例化与特定错误相对应的此异常的显式子类型。
- IllegalFormatConversionException:调用
String.format传入的参数类型与指定的标识符类型不符。 - MissingFormatArgumentException:调用
String.format传入的参数数量必标识符数量少。 - UnknownFormatFlagsException:调用
String.format时遇到未知的标识符。 - FormatFlagsConversionMismatchException:调用
String.format的标识符语法错误。 - IllegalFormatPrecisionException:调用
String.format时如果精度错误,或精度不支持。 - DuplicateFormatFlagsException:调用
String.format时标识符重复。 - IllegalFormatCodePointException:调用
String.format将具有由Character.isValidCodePoint定义的无效 Unicode 代码点的字符传递给Formatter时抛出未经检查的异常。 - UnknownFormatConversionException:调用
String.format时遇到未知的标识符(%后面不带字母情况)。 - MissingFormatWidthException:调用
String.format时需要宽度但未指定。 - IllegalFormatFlagsException:调用
String.format时给出非法的标识符组合。 - IllegalFormatWidthException:调用
String.format时给出错误的宽度。
NoSuchElementException
当各种访问器访问的元素不存在时抛出
InputMismatchException
当扫描器扫描到未知的token,或者扫描到的token与预期类型不匹配时抛出
InvalidPropertiesFormatException
读取Properties文件格式不规范时抛出,不可被序列化。
ConcurrentModificationException
一般集合等类内部会有一个字段用于检查是否在修改过程中发生了变化,如果发生会抛出。适用于fail-fast类型的接口。比如对于集合类,在修改时会不断检查元素数量是否符合接下来的预期。
TooManyListenersException
Java 事件模型的一部分,来表示对于只接受一个 Listener 的情况下继续添加额外的 Listener 时抛出。
MissingResourceException
找不到资源文件
FormatterClosedException
formatter 被关闭时抛出。
IllformedLocaleException
调用 Locale 和 Locale.Builder 方法时传入不符合 BCP 47 的格式的字符串时抛出。
EmptyStackException
调用 Stack 类中的方法,且栈空时抛出。
ServiceConfigurationError
加载 service provider 时如果出现错误抛出。
Iterator i
集合上的迭代器,Iterator 取代了 Enumeration 。提供了删除能力,并且简化了方法名。
ListIterator i
允许双向迭代的迭代器接口。它的光标位置使用位于 previous() 元素和 next() 元素之间。也就是说长度为 n 的列表对于 ListIterator 来说有 n+1 个游标位置。
需要注意,remove() 和 set(Object) 方法不是根据光标位置定义的,这两个方法会对上一次调用的 next() 或 previous() 返回的元素进行操作。
PrimitiveIterator<T, T_CONS> i
详细解释见:PrimitiveIterator in Java
Iterator 接口提供了对包装类型的迭代。如果使用 Itertor 对原始类型(int、long…)数据进行迭代,会导致频繁的拆箱和装箱。当数据集很大时会影响到迭代性能。
因此 JDK 提供了原始类型迭代器 PrimitiveIterator 。及三个子类:interface OfInt extends PrimitiveIterator<Integer, IntConsumer>、OfLong extends PrimitiveIterator<Long, LongConsumer>、OfDouble extends PrimitiveIterator<Double, DoubleConsumer>。分别单独提供了三个原始类型返回值的迭代方法 int nextIntI()、long nextLong()、double nextDouble()。及消费三种原始类型的迭代方法 forEachRemaining(IntConsumer action)、forEachRemaining(LongConsumer action)、forEachRemaining(DoubleConsumer action)。
Scanner
提供流的扫描读取能力,提供多个输入流的构造方法,多使用于 System.in() 输入流。创建实例后可以通过循环调用 hasNextInt()/hasNextLong()... 判断,nextInt()/nextLong()... 读取来扫描流内容。读取会发生阻塞。默认使用空格作为分隔符,可以定制分隔符。
内部保存一个默认 1024 大小的 CharBuffer 类型的 buf 字段,调用 hasNext*() 时会检测 buf 内数据的分隔符,并移动坐标。如果检测不到分隔符会触发从流中读取新数据的操作。读取新数据时会移除 buf 内过时数据,如果 buf 容量还不够并可能会触发翻倍(buf.size()*2)扩容。调用 hasNext*() 后会恢复坐标,以使后续可以继续调用 next*()。
TimeZone ac
GMT:Greenwich Mean Time 格林威治平时、格林威治时间。以穿过英国伦敦格林威治天文子午仪中心的一条经线作为零度参考线,简称为格林威治子午线。后被设定为本初子午线。1972年前 GMT 一直是世界时间标准(UT,UT, Universal Time)
UTC:Coodinated Universal Time,协调世界时,又称世界统一时间、世界标准时间、国际协调时间。由于英文(CUT)和法文(TUC)的缩写不同,作为妥协,简称UTC。在军事中,UTC 会使用“Z”来表示,又由于Z在无线电联络中使用“Zulu”作代称,协调世界时也会被称为”Zulu time”。
GMT = UTC+0;
夏令时:Daylight Saving Time,夏令时又称夏季时间,或者夏时制。中国曾经使用过夏令时,后废弃。夏令时会在一年中选择一天把时钟拨快一小时,之后选择一天再把时钟拨回一小时。可以使人在夏季早起早睡。
TimeZone 表示时区,可以用于计算夏令时。但这个类中没有保存太多有用信息,多数信息都是使用 sun 包中的 ZoneInfo 或 ZoneInfoFile 等。或者调用本地方法。
可以获取和使用常规时区,常规时区都保存在 ZoneInfoFile 中。也可以自定义时区。TimeZone.getTimeZone("GMT[+-]/d/d?:/d/d") 。自定义时区会创建一个对应的 ZoneInfo 对象。
SimpleTimeZone
TimeZone 的具体子类。
Locale fc
UTS#35 Unicode Locale Data Markup Language
Locale 对象表示一个具体的地理、政治、文化区域。用于使用在区域敏感的场景,比如数字、时间的显示。Locale 类实现了由 “RFC 4647” 和 “RFC 5646” 组成的 “IETF BCP 47” 制定的语言标签,支持 LDML 语言环境数据转换。
Calendar ac
用于计算日期的工具类,不能直接实例化获取,通过 Calendar.getInstance(*) 获取某个特定的实现类。
该类向外暴漏直接操作日期当中的每一项的方法,再对日期进行改动后,调用所有get等查询方法,都会触发重新计算日期。Calendar 计算日期有两种模式:宽松模式和严格模式。在宽松模式下,Calendar 会对错误的日期进行自动调整,来恢复日期的正确性,比如对“2月31日”自动调整到“2月28日”或者如果是闰年就是“2月29日”。而在严格模式下,会在日期出现错误时抛出异常。
Calendar 有两个常用的计算日期的方法 add() 和 roll() 。add 方法在增加或减少日期时,会联动更大范围的日期进行变动,比如对“1月31日”加一天,时间会变成“2月1日”。而 roll 方法在增加或减少日期时,只会影响当前级别的日期。如果发生溢出会重新计算,比如对“3月6日”滚动30天会变成“3月5日”。
GregorianCalendar
Calendar 的公历实现类
JapaneseImperialCalendar
Calendar 的日本年历实现类
Enumeration i
用于迭代、枚举所有元素,建议使用 Iterator 替代。
StringTokenizer
提供类似 String.split 功能。是个已经过时的类,不再建议使用。应该使用 String.split 或者 java.util.regx 包来代替。
EventListener i
java中的事件机制中的事件接收者。对于每个关注某个事件发生的接收者继承此接口,并定义处理该事件的方法。
EventListenerProxy ac
用于给 EventListener 提供附加绑定属性的代理类。其子类需要提供与Listener绑定属性的存储功能。并可以进行绑定和获取操作。
EventObject
java中的事件机制的事件状态对象,用于 EventListener 实现类的处理事件的方法中作为参数。
同时构造方法需提供对 java 中的事件机制的事件源的存储功能以供listener获取使用。比如button点击事件中,被点击的button就是事件源。点击就是事件状态。
ResourceBundle ac
用来解决应用程序国际化问题。调用 ResourceBundle.getBundle("myResource", new Locale("zh", "CN")); 时,会去应用程序的 Resource 目录下根据文件名寻找最佳匹配的配置文件并读取。最佳匹配是指比如找不到 myResource_zh_CN.properties 文件会尝试加载 myResource_zh.properties 。最终的降级策略会加载 myResource.properties。如果所有资源文件都加载不到会抛异常。
ResourceBundle 提供了缓存功能,不必每次都重新加载文件。并且其默认实现中不只可以加载 propertis 文件,还可以通过继承的方式来实现相同功能。如果使用继承类的方式,需要实现 handleGetObject(String) 和 handleKeySet() 方法。
PropertyResourceBundle
使用属性文件中的字符串来进行管理。使用 ResourceBudle.getBundle时加载 properties 文件就是使用这个类。
ListResourceBundle ac
子类通过重写 Object[][] getContents() 方法来初始化资源对象。第一维数组中每一项都是一对Object,第一个Object代表键,第二个Object代表值。
Observer i
Java 提供的观察者接口。被观察者需要实现 Observable 类。
Observable
Java 提供给希望被观察对象的父类,如果一个对象希望被观察状态,需要继承此类。此类提供了观察者列表,和添加观察者、通知所有观察者等方法。
PropertyPermission
用于系统属性的权限,name 是属性的名称 “java.home” ,”os.name” 等。命名约定遵循分层属性命名约定。此外,星号可能会出现在名称的末尾,跟在“.”之后,或者单独出现,以表示通配符匹配。例如:“java.*” 和 “*” 表示通配符匹配,而 “*java” 和 “a*b” 则不是。
要给一个操作授予多个权限,可以给 actions 传入英文逗号分隔的权限,比如 read,write。
Arrays
此类提供了用于操作数组的各种方法:排序、并行排序、并行前缀和、二分搜索、全等判断、填充、复制、计算哈希值、打印、转List等。还包含一个可以像访问 List 一样方法数组的静态工厂方法。
此类是 Java 集合框架的成员。
ArraysParallelSortHelpers
Arrays.parallelSort 方法的辅助类,主要提供每个基本类型 以及 Object 的静态Sorter、Merger实现。
ArrayPrefixHelpers
帮助 Arrays.parallelPrefix 方法(注:前缀和算法)提供ForkJoin操作。
DualPivotQuicksort
Dual-Pivot 排序算法实现。
ComparableTimSort
TimeSort 的一种实现类。与 TimeSort 不同的是,该类用于实现了 Comparable 接口元素的数组。
TimSort
供 Arrays 调用的 TimeSort 合并排序实现。
Formatter
用于解析用百分号修饰符占位的格式化文本,例如new Formatter().format("例子: %s,%d","参数1",2)
Formattable
FormattableFlags
Comparator i
提供各种用于比较的方法和函数式调用。比如比较大小,比较是否相等。
Comparators
为Comparator封装私有支持类。
LongSummaryStatistics
用于在流中使用的数据统计工具:
LongSummaryStatistics stats = longStream.collect(LongSummaryStatistics::new,LongSummaryStatistics::accept,LongSummaryStatistics::combine);
LongSummaryStatistics stats = people.stream().collect(Collectors.summarizingLong(Person::getAge));
DoubleSummaryStatistics
IntSummaryStatistics
Optional
对象容器类,可能活动不能包含空值。使用 Optional.of(o) 创建如果对象是空会抛出空指针。使用 Optional.ofNullable(o) 创建允许对象为空。
OptionalDouble
用于基本数据类型。
OptionalLong
OptionalInt
Spliterator i
Spliterators
用于对流的拆分 trySplit()、处理 tryAdvance(consumer)/forEachRemaining(consumer) 工具类。
SplittableRandom
与其他 Random 类不同的是,可以生成随机数序列。
ServiceLoader<S>
Java SPI机制:ServiceLoader实现原理及应用剖析
Java SPI 的工具类,用于获取服务提供方实现代码:
public static void main(String[] argus){
ServiceLoader<IMyServiceLoader> serviceLoader = ServiceLoader.load(IMyServiceLoader.class);
for (IMyServiceLoader myServiceLoader : serviceLoader){
System.out.println(myServiceLoader.getName() + myServiceLoader.sayHello());
}
}
StringJoiner
StringJoiner sj = new StringJoiner(":", "[", "]");
sj.add("George").add("Sally").add("Fred");
String desiredString = sj.toString();
//输出 [George:Sally:Fred]
//也可以在Stream中通过Collectors.joining()调用
stream.collect(Collectors.joining(":", "[", "]"))
Timer
使用时继承 TimerTask,然后调用 schedule() 。与 JDK 5 中的单线程 ScheduledThreadPoolExecutor 相似。但是 ScheduledThreadPoolExecutor 也可以配置多个执行线程。每个 Timer 实例都拥有一个执行线程和一个任务队列。执行线程在 new Timer() 时启动,通过调用 schedule() 添加任务。任务不宜过多,或者执行耗时过长,不然会影响其他任务执行。
提供以下功能:
- 在指定时间执行任务
- 在指定时间执行任务,后续间隔指定时间重复执行
- 启动任务后,延迟时间执行
- 启动任务后,延迟时间执行,后续间隔指定时间重复执行
TaskQueue
//优先级队列表示为一个平衡的二叉堆:queue[n] 的两个孩子是 queue[2*n] 和 queue[2*n+1]。
//优先级队列在 nextExecutionTime 字段上排序:具有最低 nextExecutionTime 的 TimerTask 在队列 [1] 中(假设队列非空)。
//对于堆中的每个节点 n,以及 n、d 的每个后代,n.nextExecutionTime <= d.nextExecutionTime。
private TimerTask[] queue = new TimerTask[128];
TimerTask
实现了 Runnable 接口
TimerThread
继承了 Thread 类
BitSet
内部使用 long 数组作为存储。使用 bit 位来存储大量的 bool 信息。
Collections
提供了多个静态工具方法用于操作集合。
- 排序
- 二分查找
- 反转,以指定位置为中心两边互换
- 打乱
- 交换集合内元素位置
- 填充集合
- 拷贝集合
- 计算最大、最小元素
- 替换元素
- 计算元素坐标
- 包装其他集合为同步安全、不可修改
- 生成心集合
- 检查集合元素类型
Random
用于生成伪随机数的工具。该类使用 48 位种子,使用线性同余公式进行计算。如果用相同的种子创建两个 Random 实例,并且对每个实例进行相同的方法调用,他们会生成相同的数字序列。该类是线程安全的。
可能包装的 Math.random 更便于使用,如果需要跨线程访问可以使用 ThreadLocalRamdom ,如果需要获取更安全的随机数,可以使用 SecureRandom。
Currency
用于国际化下的货币类型。通过 getInstance 构建。
Tripwire
在流操作中如果属性 org.openjdk.java.util.stream.tripwire设置为 true 则在对原始子类型特化进行操作时,如果出现原始值的装箱,则会报告诊断警告。
Base64
一种用64个可打印字符表示二进制数据的编码解码方式,不具备加密能力。常用与基于文本的协议无法传输二进制流的情况,比如 http 协议中的 url 就是纯文本的。
不可被实例化,通过调用 Base64.getXXEncoder() 获取对应的编码解码器。
Objects
提供一组静态工具方法来操作对象进行 比较、判等、判空。
UUID
用于在分布式环境下生成不会重复的唯一标识符。
Date
Date 类代表一个特定的时间点,精度为毫秒。
在 JDK 1.1 之前,Date允许将日期解释为年月日时分秒,还允许格式化和解析日期字符串。但是这些功能不适合国际化。从 JDK 1.1 开始,应该使用 Calendar 类在日期和时间字段之间进行转换,同时使用 DateFormat 来格式化和解析日期字符串。