数据结构
简单动态字符串
SDS 全名 SImple Dynamic String
sds.h/sdshdr 结构
struct sdshdr {
//记录buf数组中已使⽤字节的数量
//等于SDS所保存字符串的⻓度
int len;
//记录buf数组中未使用字节的数量
int free;
//字节数组,⽤于保存字符串
char buf[];
};
与 c 语言不同
- 在字符串末尾都保留空字符以兼容传统的c字符串操作
- 存储字符串长度信息,可以直接获取sds长度。
- 可以杜绝缓冲区溢出,sds API会检查空间。而string API如果程序员疏忽没分配足够空间会溢出
- sds修改时会预分配空间避免数据库频繁修改数据时的空间申请。
-
如果对 SDS 进行修改之后, SDS 的长度( 也即是 len >属性的值) 将小于1MB,那么程序分配和 len 属性同样大小的未使用空间, 这时 SDS len 属性的值将和 free 属性的值相同。举个例子, 如果进行修改 之后, SDS 的 len 将变成 13 字节, 那么程序也会分配 13 字节的未使用空间,SDS 的 buf 数组的实际长度将变成 13+ 13+ 1= 27 字节( 额外的一字节用 于保存空字符)。
-
如果对 SDS 进行修改之后,SDS 的长度将大于等于 1MB, 那么程序会分配 1MB 的未使用空间。 举个 例子,如果进行修改之后,SDS的 len 将变成 30MB,那么程序会分配 1MB的未使用空间,SDS的 buf 数组的实际长度将为 30MB+ 1MB+ 1byte。
-
- sds二进制安全,sds以二进制方式处理buf内容,而string必须符合某种编码,字符串中不能出现空字符,所以不能保存blob数据。
- 因为sds也是以空字符结尾,可以兼容部分string原⽣生函数。
链表
字典
dict. h/ dict 结构
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
//哈希表
dictht ht[2];
//rehash索引
//当rehash不在进行时,值为-1
in trehashidx;
} dict;
dict. h/ dictht 结构
typedef struct dictht
{
//哈希表数组
dictEntry **table;
//哈希表⼤小
unsigned long size;
//哈希表⼤小掩码,⽤于计算索引值
//总是等于size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
} dictht;
typedef struct dictEntry
{
//键
void *key;
//值
union{ void *val; uint64_ tu64; int64_ ts64; } v;
//指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
type属性是一个指向dictType结构的指针, 每个dictType结构保存了一簇用于操作特定类型键值对的函数, Redis 会为用途不同的字典设置不同的类型特定函数ht属性是一个包含两个项的数组,数组中的每个项都是一个dictht哈希表,一般情况下,字典只使⽤用ht[0]哈希表,ht[1]哈希表只会在对ht[0]哈希表进⾏ rehash 时使用。- 除了
ht[1]之外,另一个和 rehash 有关的属性就是rehashidx,它记录了 rehash ⽬前的进度,如果⽬前没有在进⾏ rehash, 那么它的值为-1。
rehash
- 为字典的
ht[1]哈希表分配空间, 这个哈希表的空间⼤小取决于要执⾏的操作,以及ht[0]当前包含的键值对数量( 也即是ht[0].used属性的值):- 如果执⾏的是扩展操作,那么
ht[1]的⼤小为第一个大于等于ht[0].used* 2 的 2 n( 2的 n 次⽅方 幂); - 如果执⾏的是收缩操作,那么
ht[1]的⼤小为第一个大于等于ht[0].used的 2 n。
- 如果执⾏的是扩展操作,那么
- 将保存在
ht[0]中的所有键值对使用渐进式的方式 rehash 到ht[1]上面: rehash 指的是重新计算键的哈希值和索引值, 然后将键值对放置到ht[1]哈希表的指定位置上。- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量 rehashidx, 并将它的值设置为
0, 表示 rehash 工作正式开始。 - 在 rehash 进行期间, 每次对字典执行添加、 删除、 查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将
ht[0]哈希表在 rehashidx 索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后,程序将 rehashidx 属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被rehash 至ht[1],这时程序将 rehashidx 属性的值设为-1, 表示 rehash 操作已完成。
- 为
- 当
ht[0]包含的所有键值对都迁移到了ht[1]之后(ht[0]变为空表), 释放ht[0], 将ht[1]设置为ht[0], 并在ht[1]新创建一个空白哈希表,为下一次 rehash 做准备。当以下条件中的任意一个被满足时,程序会自动开始对哈希表执行扩展操作:- 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 1 。
- 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因⼦大于等于 5 。
其中哈希表的负载因子可以通过公式: # 负载因子=哈希表已保存节点数量/ 哈希表大小
load_ factor = ht[0].used / ht[0].size
跳跃表
跳跃表( skiplist)是⼀ 种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。跳跃表支持平均 O(logN)、最坏 O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
和链表、 字典等数据结构被广泛地应用在 Redis 内部不同,Redis 只在两个地⽅用到了跳跃表,一个是实现有序集合键,另一个是在集群节点中用作内部数据结构,除此之外,跳跃表在 Redis⾥面没有其他⽤途。
整数集合
typedef struct intset{
//编码⽅方式
uint32_t encoding;
//集合包含的元素数量量
uint32_t length;
//保存元素的数组
int8_t contents[];
} intset;
每当我们要将⼀个新元素添加到整数集合⾥面,并且新元素的类型比整数集合现有所有元素的类型都要⻓时,整数集合需要先进⾏升级(upgrade),然后才能将新元素添加到整数集合⾥面。升级整数集合并添加新元素共分为三步进行:
- 根据新元素的类型,扩展整数集合底层数组的空间⼤小,并为新元素分配空间。
- 将底层数组现有的所有元素都转换成与新元素相同的类型,并将类型转换后的元素放置到正确的位上,⽽且在放置元素的过程中,需要继续维持底层数组的有序性质不不变。
- 将新元素添加到底层数组⾥面。
压缩列列表
每个压缩列列表节点由 previous_ entry_ length、 encoding、 content 三个部分组成
previous_ entry_ length
节点的 previous_entry_length 属性以字节为单位,记录了压缩列表中前一 个节点的长度。previous_entry_length 属性的长度可以是 1 字节或者 5 字节
encoding
- 一字节、 两字节或者五字节长, 值的最高位为
00、01或者10的是字节数组编码: 这种编码表示节点的content属性保存着字节数组, 数组的长度由编码除去最高两位之后的其他位记录; - 一字节长, 值的最高位以
11开头的是整数编码:这种编码表示节点的content属性保存着整数值, 整数值的类型和长度由编码除去最高两位之后的其他位记录;
content
节点的 content 属性负责保存节点的值,节点值可以是一个字节数组或者整数,值的类型和长度由节点的 encoding 属性决定。
可能会有连锁更新,要注意的是,尽管连锁更新的复杂度较高,但它真正造成性能问题的几率是很低的:
- ⾸先,压缩列表里要恰好有多个连续的、⻓度介于 250 字节至 253 字节之间的节点,连锁更新才有可能被引发,在实际中,这种 情况并不多见;
- 其次,即使出现连锁更新,但只要被更新的节点数量不多,就不会对性能造成任何影响:比如说,对三五个节点进行连锁更新是绝对不会影响性能的;
对象
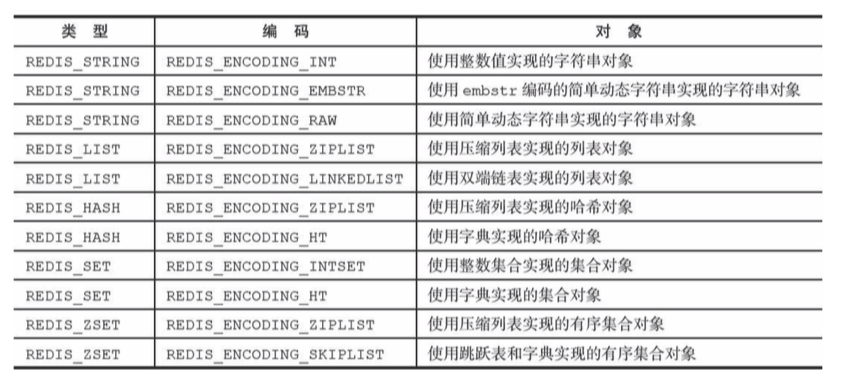
Redis内部有一些用来支撑服务的数据结构,并基于这些数据结构创建了一个对象系统来实现键值对数据库。每种对象可以由多种数据结构实现,会根据存储内容的类型可大小动态转化对象内部使用的数据结构,从而优化不同场景的使用效率。Redis对象统还实现了基于引用计数内存回收制,当程序不再使用某个对象的时候,这个对象所占用内存就会被自动释放;另外,Redis还通过引用计数实现了对象共享机制,这一机制可以在适当的条件下,通过让过个数据库键共享同一个对象来节约内存。对象带有访问时间记录信息,该信息可用于计算数据库的空转时长。
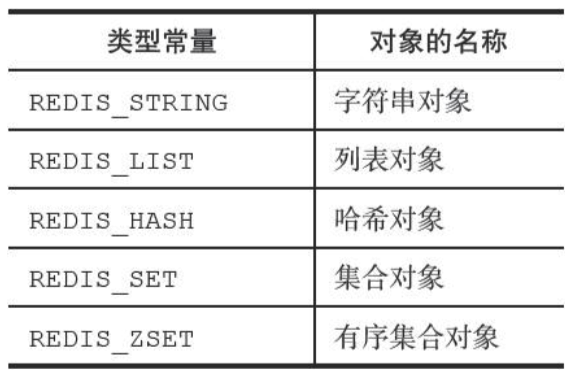
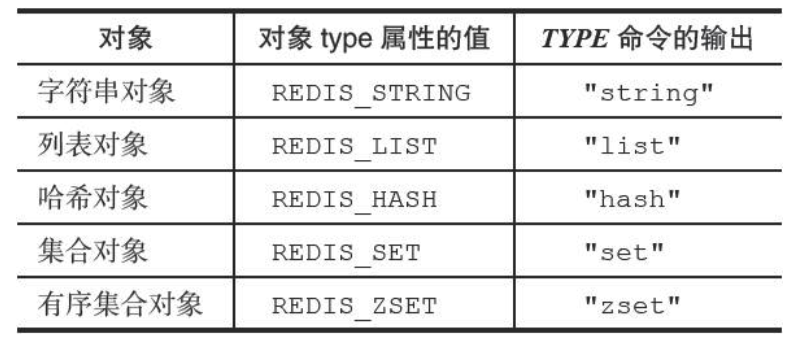
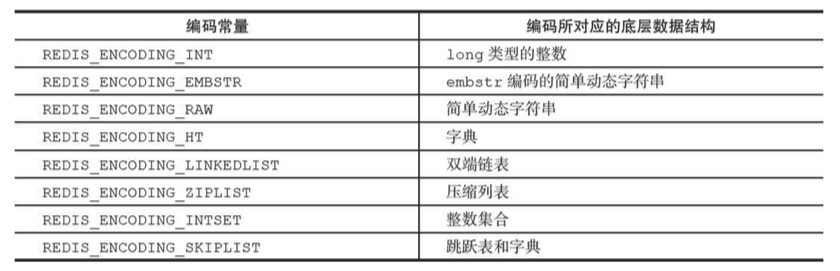
对象类型
typedef struct redisObject {
//类型
unsigned type:4;
//编码
unsigned encoding: 4;
//指向底层实现数据结构的指针
void *ptr;
//....
} robj;
数据库
初始化服务器时会根据dbnum属性来创建N个数据库,数据库在代码中的表现就是一个数组。client通过显示的select X命令来切换数据库。
键空间
数据库所有的键值对都保存在reidsDb结构中的字典里在对键值的操作时都要执行一些维护操作如更新hit和miss次数,更新LRU时间,删除过期键等。如果client使用WATCH命令监控了某个键,修改还会标记键为脏键,每次修改更新脏键计数器
超时时间
SETEX命令只能用于字符串
- EXPIRE <key> <ttl> 命令⽤于将键key的生存时间设置为ttl秒。
- PEXPIRE <key> <ttl> 命令⽤于将键key的生存时间设置为ttl毫秒。
- EXPIREAT <key> <timestamp> 命令用于将键key的过期时间设置为timestamp所指定的秒数时间戳。
- PEXPIREAT <key> <timestamp> 命令用于将键key的过期时间设置为timestamp所指定的毫秒数时间戳。
redisDb结构的expires字典保存了数据库中所有键的过期时间,我们称这个字典为过期字典:
- 过期字典的键是一个指针,这个指针指向键空间中的某个键对象(也即是某个数据库键)。
- 过期字典的值是一个
longlong类型的整数,这个整数保存了键所指向的数据库键的过期时间——一个毫秒精度的UNIX时间戳。
RDB持久化
将Redis在内存中的数据库状态保存到磁盘里面,避免数据意外丢失。可以手动执行,也可以根据服务器配置定期执行。RDB文件是一个经过压缩的二进制文件。
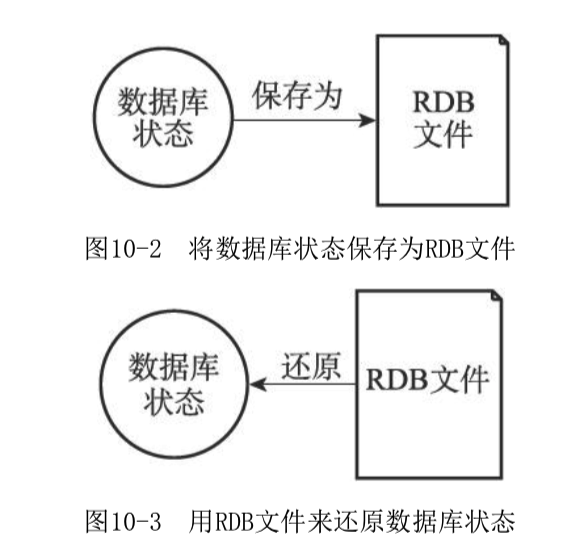
RDB文件的创建与载入
有两个Redis命令生成RDB文件,SAVE和BGSAVE。SAVE命令会阻塞Redis服务器的进程,直到RDB文件创建完。BGSAVE会派生出一个子进程来创建RDB文件,同时在完成之前拒绝SAVE命令和BGSAVE命令。RDB文件的载入工作是在服务器启动时自动执行,不需要单独命令。
因为AOF文件的更新频率通常比RDB文件高,所以如果开启了AOF持久化功能会优先使用AOF,只有在AOF关闭时才使用RDB功能。
AOF持久化
AOF(Append Only File),通过保存Redis服务所执行的写命令记录数据库的状态。AOF文件内容是以Redis的命令请求协议格式保存的文本格式。
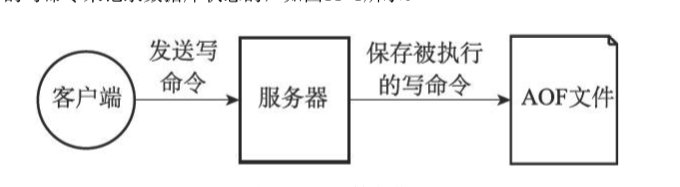
AOF的实现可以分为命令追加、文件写入、文件同步(sync)三个步骤。
Redis主进程在每次事件循环结束会触发刷新AOF的函数,函数内部根据配置是内次刷盘,还是每秒刷盘,还是从不刷盘由系统决定。默认为每秒。
Redis通过创建一个不带网络连接的伪客户端读取AOF里面的命令发送到Redis来从AOF文件还原.
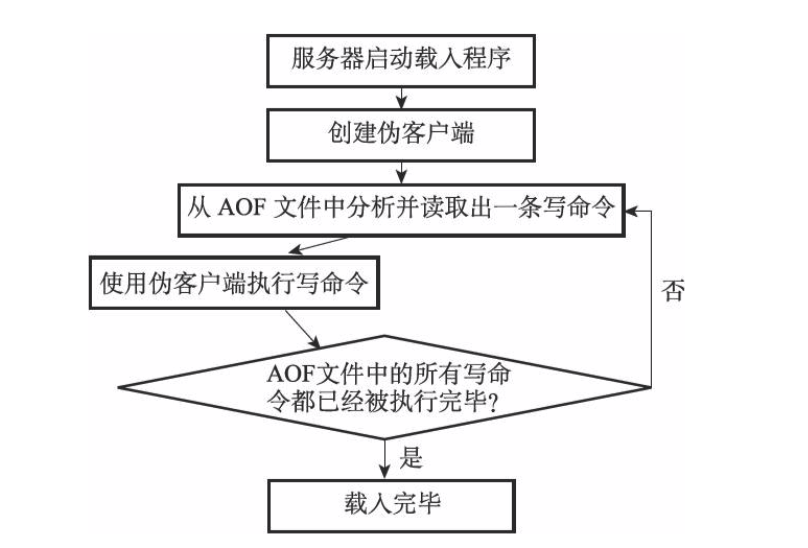
AOF重写
为了避免AOF文件体积过大,Redis提供了AOF文件重写功能。会使用一个子进程读取数据库当前状态生成写入命令,并写入新的AOF文件。由于子进程和主进程同时进行,为了避免新命令改变数据库现有状态,在子进程启动期间Redis会开启一个重写缓冲区。当子进程完成后,通知主进程,然后主进程将重写缓冲区的内容追完到新的AOF文件。然后对新的AOF文件改名来原子的覆盖现有AOF文件。
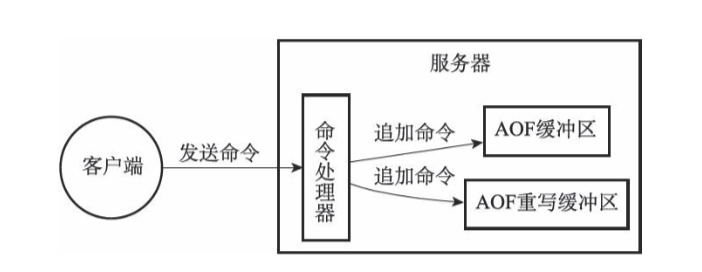
事件
⽂件事件通过实现epoll/kqueue/evport套接字的监听,和时间事件在同一个循环中执行。计算下一个到达的时间事件时间,传入监听的timeout中,避免文件事件阻塞时间事件。redis的时间事件不是非常的准时。
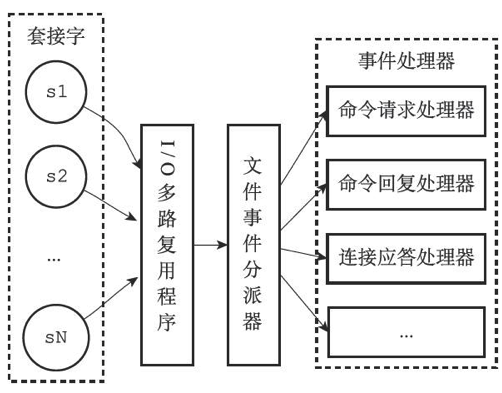
文件事件
基于Reactor模式的称为“⽂件事件处理器”的⽹络事件处理器。以单线程的方式运行,通过io多路复用监听多个socket。这样既可以实现高性能的网络通信模型也可以保持redis内部单线程设计的简单性与其他单线程模块对接。
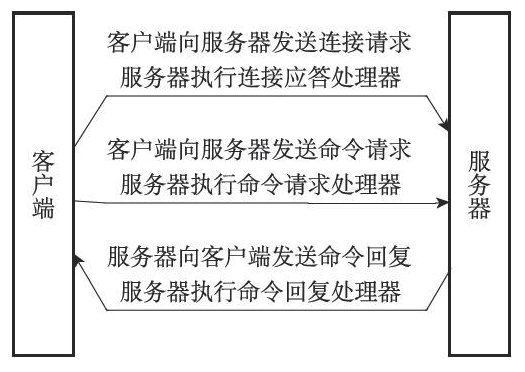
一次完整的客户端与服务器连接
时间事件
所有的时间事件都存放在一个⽆序链表中,时间事件执行器遍历整个链表来选择已到达的事件。 因为目前Redis服务器只有serverCorn⼀个时间事件,在benchmark模式下也只有两个时间事件,所以⼏乎无影响。